Duplicate Detection
Duplicate detection allows you detect, filter and remove duplicate datapoints in your datasets.
The Atlas duplicate detection capability uses your datasets embeddings to identify datapoints that are near-duplicates and then gives you the ability to take action.
Atlas automatically groups similar embeddings into semantic clusters for duplicate detection. Each datapoint is assigned to one of three categories:
- If a cluster has only one point, that point is labeled as a singleton
- For clusters with multiple points, one arbitrary point is labeled as a retention candidate
- The remaining points in multi-point clusters are labeled as deletion candidates
This clustering allows you to quickly identify and deduplicate your data.
Duplicate detection can be used in the web interface or via the API.
Duplicate Detection in the Browser
Enabling duplicate detection
Duplicate detection is enabled by default when uploading data through the web browser. Atlas will automatically identify potential duplicates after your map is built.
Learn about various configuration operations for duplicate detection in the API Reference.
Filtering duplicates
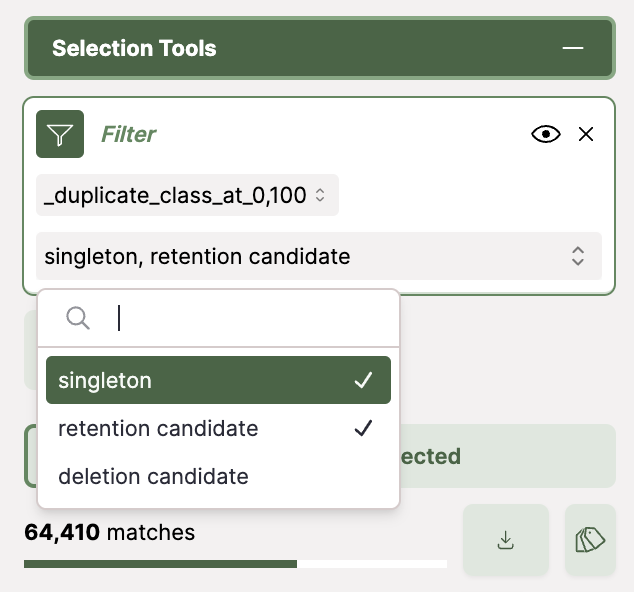
Click the filter tool in the selection pane and the select Duplicate Class. Duplicate detection assigns each datapoint into one of three categories:
- Deletion candidates: The set of points you can remove because they are near-duplicates of other points.
- Retention Candidates: The set of points that are part of a duplicate cluster and are the single point from that cluster chosen to be retained.
- Singleton: The set of datapoints that have no near-duplicates in the dataset.
Form a compound selection of the retention candidates and singleton datapoints and then download the selection.
Duplicate Detection with the Atlas API
Duplicate detection is enabled by default when creating an Atlas map using the Nomic Atlas Python SDK:
from nomic import AtlasDataset
dataset_identifier = "my-dataset" # for my-dataset in the organization connected to your Nomic API key
# dataset_identifier = "<ORG_NAME>/my-dataset" # for my-dataset in other organizations you are a member of
atlas_dataset = AtlasDataset(dataset_identifier)
atlas_dataset.add_data(my_data)
# Duplicate detection runs by default
atlas_dataset.create_index(indexed_field="text")
Configuring duplicate detection (Optional)
While duplicate detection runs by default, you can fine-tune its behavior by providing NomicDuplicatesOptions to the create_index method. The main parameter you might adjust is the duplicate_cutoff threshold. Smaller thresholds result in duplicate clusters containing datapoints that are closer to exact matches. The default threshold is 0.1.
from nomic import AtlasDataset, NomicDuplicatesOptions
# ... (Dataset creation and data addition as above) ...
atlas_dataset.create_index(
indexed_field="text",
duplicate_detection=NomicDuplicatesOptions(
tag_duplicates=True,
duplicate_cutoff=0.2, # Adjust the similarity threshold
)
)
See API Reference for more configuration details.
Access Duplicate Information
Once your map is built, you can access duplicate information programmatically.
from nomic import AtlasDataset
atlas_dataset = AtlasDataset(dataset_identifier)
atlas_map = atlas_dataset.maps[0]
duplicate_info_df = atlas_map.duplicates.df
print(duplicate_info_df)
index duplicate_class cluster_id
0 100001 singleton 16492
1 100011 singleton 16017
2 100016 singleton 7826
3 100020 singleton 5044
4 100030 retention candidate 412
... ... ... ...
19995 99721 singleton 9218
19996 99730 deletion candidate 371
19997 99918 singleton 13311
19998 99926 singleton 13725
19999 9997 singleton 3866
... ... ... ...
Curate data with deletion candidates
You can use your deletion candidates from the duplicate detection results and curate a new dataset without them.
# Get the original data from the map
old_df = atlas_map.data.df
# Get a list of IDs for datapoints marked as deletion candidates
# This will keep only singletons and retention candidates
ids_to_remove = atlas_map.duplicates.deletion_candidates()
if ids_to_remove:
new_df = old_df[~old_df['id'].isin(ids_to_remove)]
new_identifier = dataset_identifier + "-without-duplicates"
new_dataset = AtlasDataset(
new_identifier,
description=f'Map of {dataset_identifier} without duplicates',
)
new_dataset.add_data(new_df)
new_dataset.create_index(
indexed_field="text"
)